

type
status
date
slug
summary
tags
category
icon
password
打着“全球首款通用型AI Agent产品”的旗号,Manus成功登顶AI圈子最火焦点。当然,最近两天关于Manus的声音良莠参半,大家争论的核心其实是AI产业的发展路线之争:究竟是模型参数的“军备竞赛”,还是工程化落地与场景价值的“实用主义”?。这篇内容作者尝试换个角度讨论:站在客观视角,从产品、技术、营销三个维度,分析Manus的给AI 应用层面带来的最新进展。
产品
这部分作者打算先从2个不错的官网案例开始,然后再从优缺点的角度详细的展开产品分析。
2个用例:原码研究、股票分析
官网给出了6个主题共计51个case,覆盖普通用户通用的使用场景,比如生活、办公、自媒体;还包括的面向专业人士的应用场景,比如数据分析、行业研究、教育教学。
这里重点讨论其中的2个Case:开源项目研究、股票分析。
Github开源项目研究
Prompt提示词:
Manus输出结果:
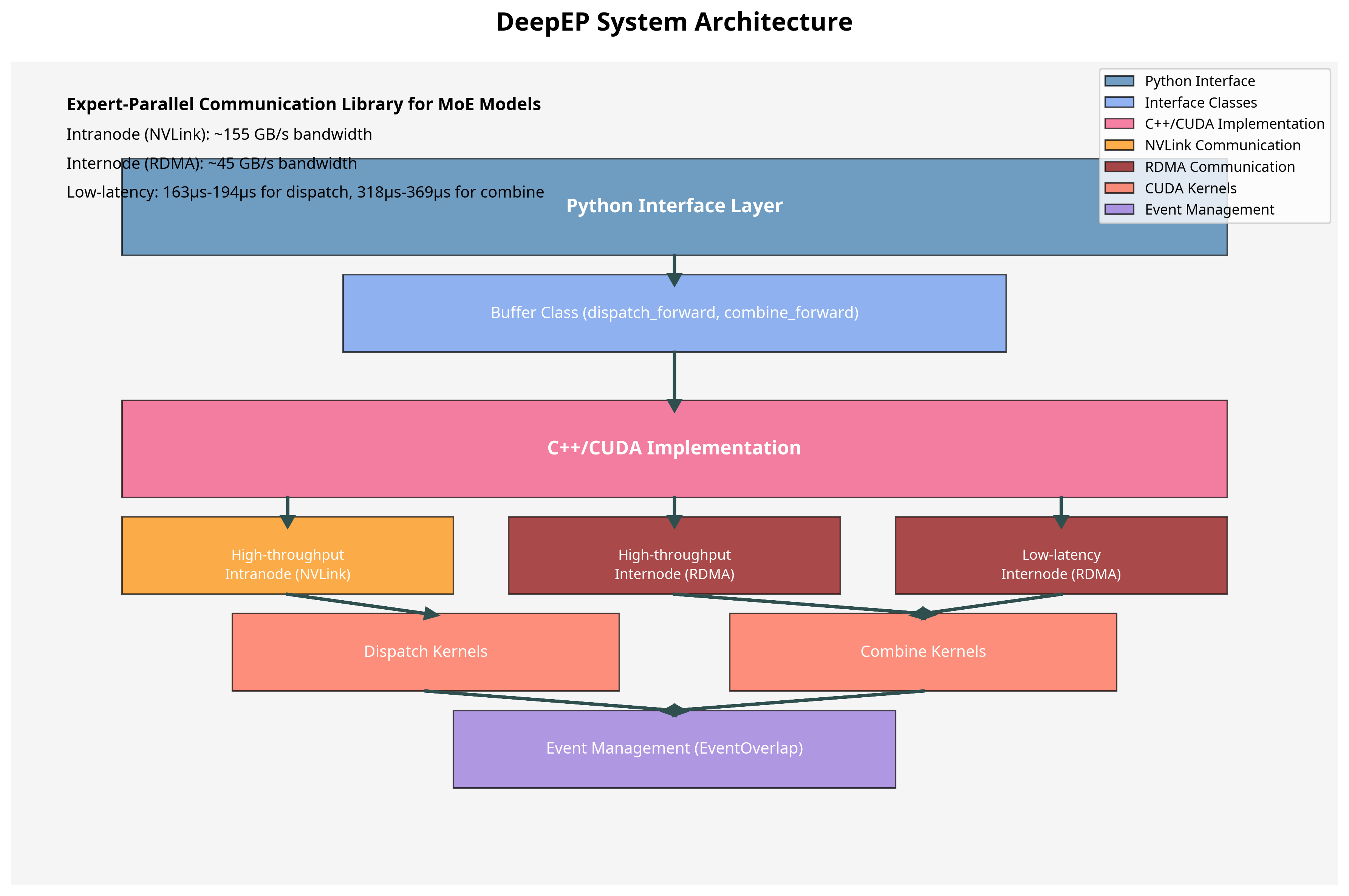
Manus会首先下载开源库的原码,然后进行代码级别的分析,最终会输出一个架构图。
一图剩千言,对于软件行业的技术工程师来讲,技术的迭代发展,经常需要研究新出现库的源码,与产品通常有UI不一样,有些库更多是设计思想级别的工程化实践,不花点时间或者技术储备有限的话,很难在短时间内分析出开源库的框架,而Manus直接给出的框架图,这将大大提高工程师们研究新技术的时间效率。
不足的地方,作者并没有看到在代码性能方面的分析,现实中工程师对于要集成进工程中的库,要求不仅仅是能看明白代码,更需要从性能、安全等方面深度考量。
结果部分截图:
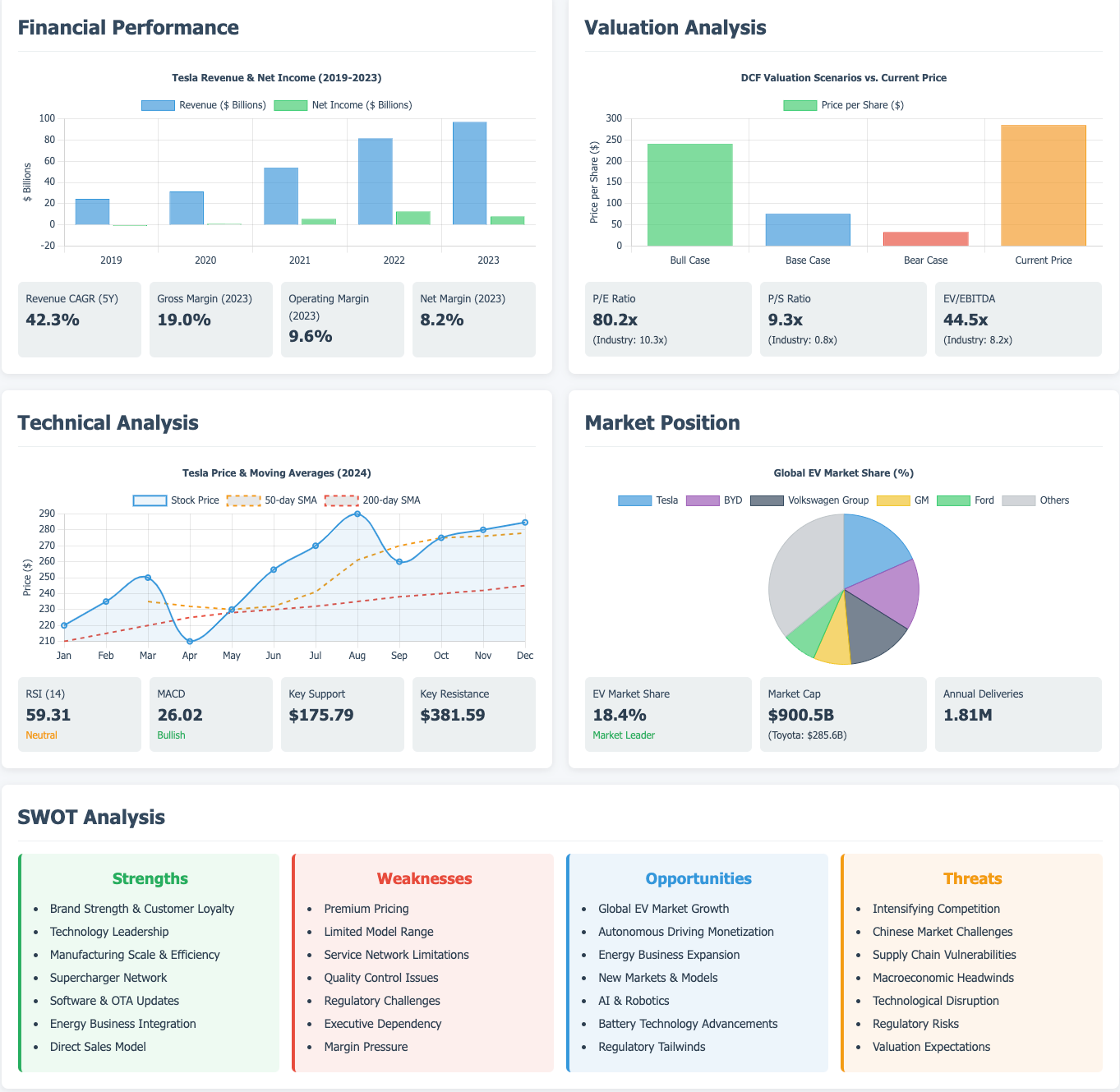
特斯拉股票分析
这个场景中,Mauns直接将分析的结果形成一个Web版本的报告,并直接部署在服务器上,从而让报告能够方便的分享和传播。
Prompt提示词:
Manus输出结果:
分析的结果也是相当惊艳,不仅给出了很直观的投资建议,还给出定性定量的详细分析,比如财务表现、价值分析、技术分析、市场地位,以及经典的SWOT(Strengths、Weakness、Opportunities、Threats)分析。
当然SWOT部分的分析,个人感觉比较偏宏观一些,没有相对细节一点的分析和展开。
结果部分截图:(感兴趣的读者可以访问这里具体查看)
Manus优缺点分析
优点:
- 产品交互方式惊艳:用户给出提示词之后,任务的分析、拆解、编码、执行过程,完全对用户开放且透明,不需要用户干预且输出结果也很直观。
- 模拟人类行为:相比更适用特定任务类型的类人的机器人,模拟人类行为的方式,模拟人类与浏览器的交互方式,可以更好的适用通用任务类型。
- 可视化能力出众:数据分析类型的任务上,通过更具设计感的可视化图表,直观的展现数据之间的数学关系。
- 集成的代码运行环境:Manus直接集成了基于Linux的虚拟机和Python运行环境,这就让需求的分析、编程实现、运行及结果更完美的融进Agent的执行链路中,极大的扩展了Manus的能力边界,从这一点上来说,对应到了Manus宣传语当中说的“第一款通用型AI Agent”。
不足:
TODO List会一定程度上导致结果趋向平庸:TODO List的方式带来的好处就是结果的快速收敛,但这也带来AI探索在发散方面的丧失,特别是行业分析方向,一定程度上需要根据获得的信息来进行动态的调整。
资料的筛选和合并占据较大的上下文窗口:受限于大模型能力与上下文窗口,资料的筛选和最终结果的合并与整理会消耗掉大量的Token,这会影响最终结果趋向于平庸。
数据采集阶段的成本不低:Manus使用模拟浏览器搜素、点击、滚动、文字图表OCR的方式获取原始的数据,这在时间成本和资源成本方面,都有不小的消耗。
技术
跟ChatGPT和Claude这样能力强悍的通用大模型不一样,Manus更多是在AI落地的“最后一公里”:工程级别的实践。只有资本才看重技术的护城河方面,作者认为技术的本质应该回归实用性,即解决用户问题。
从这个角度讲,被认为是“套壳”的Manus就是有价值的。Manus的出现让“自然语言调用算力达成目标”这件事向前又推进了一步。那Manus是如何进行技术实践的?
Manus技术架构
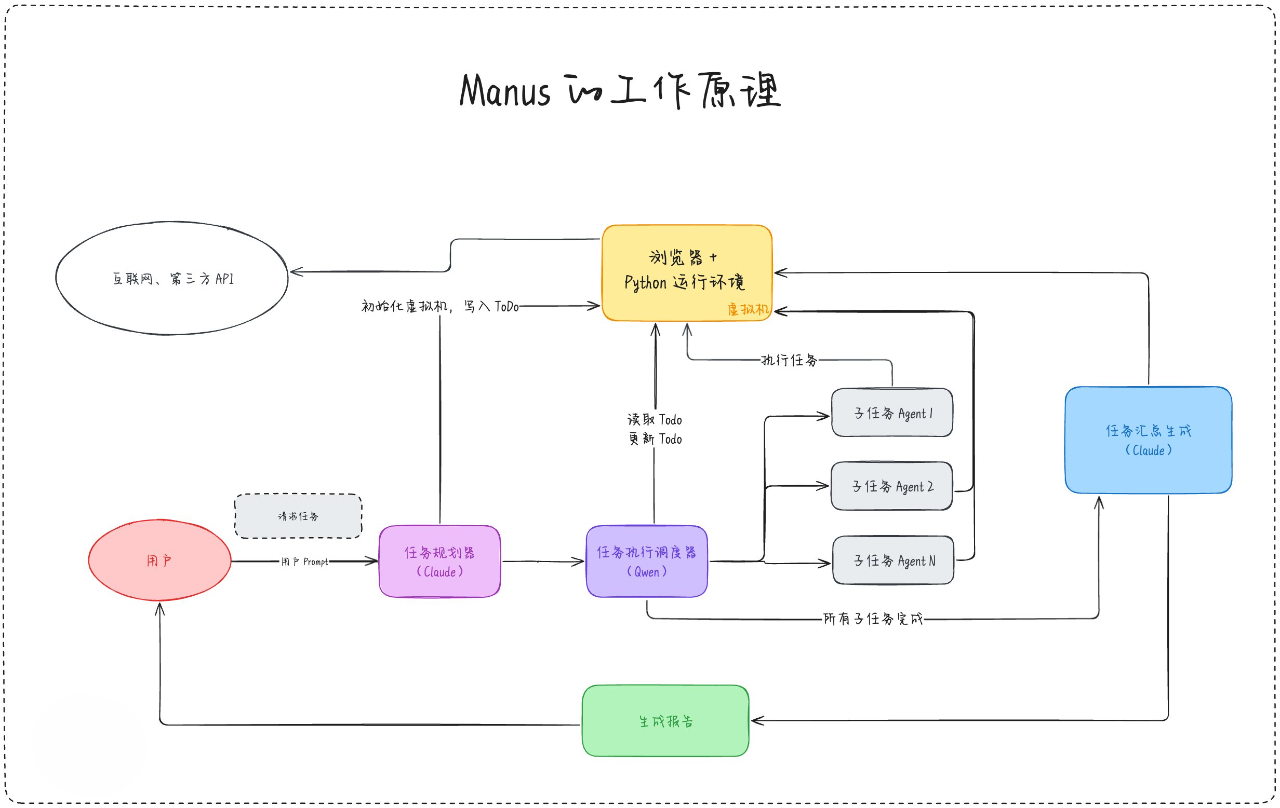
- 虚拟机:一个 Linux 系统的虚拟机,包含两个核心组件: • Chrome浏览器,用来访问网页。 • Python运行环境,可以执行脚本分析数据,可以启动一个网页运行环境
- 任务规划器:根据用户输入的任务请求,拆分成 TODO List,这一块是整个Agent的链路最重要的环节,必须要求模型有很强的推理能力,推测可能是相对经济实惠的Claude 3.7 Sonnet 。
- 任务调度器:根据上一步的TODO List逐一执行每个任务,根据任务的类型去调度最合适的 Agent。这一步重点在Agent选择上面,所以不需要太强大的模型,开源模型Qwen就可以。
- 内置AI Agents:Manus 内置了很多不同任务领域的Agent,比如最复杂的应该是类似于OpenAI Operator的网页浏览Agent,比如根据API检索特定数据的Agent。每个Agent在任务完成后会把任务结果写到虚拟机。
- 任务汇总生成器:每个子任务执行完成后,任务调度器通知任务汇总生成器,任务汇总生成器到虚拟机读取 ToDo List 以及各个子任务的生成结果,把这些结果汇总整理生成最终结果。结果根据任务要求,可能是一份调研报告,也可能是网页程序。由于这一步要求有极强的推理能力和语言能力,所以这一步骤的模型需要比较强,猜测可能是Claude 3.7 Sonnet。
根据以上对Manus实现的拆解可以看出,制约其能力是关键技术在于大模型能力和Agent能力,而Agent又受制于大模型的能力。所以Manus的本质,是基于大模型能力在工程级别的创新实践。
AI产品的护城河在哪里?
既然是基于现有技术能力的工程级别的实践,那么,在AI吸引了绝大部分的资金、工程师、大众注意力的当下,很快就会有“山寨”版的Manus,事实上,Manus发布的第二天就出现了开源版本的OpenManus,第三天某AI开源社区就开直播复刻Mauns工程代码实践。
对于AI产品来说,护城河主要有两点:从AI角度看是基因三件套算力、算法、数据;从产品角度看是用户体验。
AI基因三件套:
算法:
比如OpenAI的Deep Research,虽然开源或者商业的竞品很多,但是效果比它好的还没有第二家,核心原因就是其用来规划任务、选择工具、汇总任务结果的模型是他家最强的推理o3模型,可能也是业界最强的推理模型,无论是推理能力还是上下文长度都超过了公开的 Claude 3.7 Sonnet 模型,同时他们还基于o3针对Deep Research做了大量的强化学习训练,让模型在执行任务和生成内容都可以取得很好的效果,算法就是OpenAI的护城河。
数据:
比如说Google,虽然模型不一定有OpenAI的强,但是它们家的数据及搜索能力是最强的,可以获取到优质的数据源,效果上也还不错,数据就是Google的护城河。
算力:
在”Scaling law“支配下的AI产业,高昂硬件成本让算力成为通用型大模型企业的护城河。OpenAI拥有的算力是35万块NVDIA A100,Elon Musk的Gork拥有算力是20万块NVDIA H100…零一万物已经退出了通用大模型的玩家序列。
用户体验:
这里将用户体验,并不是传统意义上的UI交互层面的体验,而是基于大量用户使用数据进行个性化优化后的优化体验,就是说很懂用户想要什么。
比如,经常被比作是“套壳”的 AI 产品Perplexity,算法(模型)比不过 OpenAI,数据比不上Google,但依然在AI搜索中占有很重要的地位,它依赖的是独特的用户体验,更懂用户,更好的提供了用户想要的搜索结果。
类似的例子还有AI编辑器 Cursor,它也是靠用户体验来吸引用户,虽然它的Composer功能很快就被竞争对手学习借鉴过去了,但是它的自动补全功能却一直没被竞争对手超越。作者是使用感受是,每次修改一点,它就能自动给出要完成的下一步操作,大部分时候,它的建议都是我想要的,就是Cursor懂你心中所想,这是在以往其他IDE中完全没有过的体验。
Perplexity和Cursor这类AI“套壳”产品的护城河,就在于它有大量用户数据沉淀后的用户体验。
AI Agent爆发的年代,如何搭建AI产品的护城河?
根据以上护城河的讨论,算法(这里特指通用型算法)依赖于原创性的技术突破,如Transformer架构;算力需要庞大的资金加持,属于大厂玩家专属。对于广大的应用层玩家来说,能够用来构建护城河的思路还有两个:数据和用户体验。
对于Manus,有人觉得惊艳,有人觉得也就那样,有人觉得没有达到自己期待的样子。其实这一切都因为目前AI还处于很早期,不是 Manus 做得不够好,而是受限于目前AI大模型的能力,只能做到这样。 但即使是目前这样,已经让很多人觉得惊艳了。 不能因为暂时实现不完美,就不推出产品。 有些人开发产品的心态是,不打磨到100分就不推出来。 其实产品永远有值得改进的点,难到那就一直改进,一直不推出吗?
最近听说了一种说法:生态位。就是说先推出产品,先占住这个生态位,然后不断迭代,不断提升能力,就能够做得越来越好。 相似的例子是Cursor,他们最开始发布的产品,效果也没有那么好,没有那么惊艳,但是他们等到了claude sonnet 3.5 这个模型的出现,全球各地开发者都在自来水推荐 Cursor 。 试想一下,如果Cursor 等到了claude sonnet 3.5发布之后,才去开始动手做,那么机会还会是 Cursor 的吗?
集合生态位的思想,先吸引来用户,留住用户,形成口碑,把这些用户数据沉淀下来进一步提升用户体验,以后随着模型能力的升级一起更新迭代,就能真正形成自己的护城河,再难被其他竞品超越。
Manus 开了个好头,但挑战还是不小的,开源的实现、商业上的山寨版本应该很快就要出来了,用户的热度也会消散的很快,一旦有新的热点马上就会去追逐新的热点了,就像你还记得 OpenAI 家的 Operator吗?
未来,对于Manus或者这类产品来说,想形成自己的护城河,不仅仅是要在用户产品体验上的创新,还需要有用户数据上的沉淀,把这种数据变成一种飞轮效应,即基于用户的数据做出更懂用户的体验,更懂用户的体验吸引更多的用户使用。
营销
没有营销专项资金,自己却引爆话题传播,估计节约了上亿的营销费用。
据说Manus产品线内部有组织KOL演示会,其实就相当于组织影评人观看的试映会一样。产品惊艳KOL 也愿意分享给粉丝,出圈后还可以反向蹭 Manus 的热度,这是一种是双赢的合作。
除此之外,短时间内,Manus建设起来的对外发声的渠道已有:官网、公众号、社区(Discord)、社交媒体(X、即刻)、社群(各种讨论群)。
在如今各个老板、主持人、明星等都亲自下场,玩起流量的当下环境,对流量的理解和善用,是把你的核心的产品推而广之的强大“武器”,这里的产品可以是AI应用、可以是你的Paper、可以是电商商品,或者也可以是你的观点。
作者想从营销角度讨论Manus的原因,就是在于学习Mauns的流量打法。这种打法的内核是,一个具有硬核属性的产品,通过KOL们的首轮扩散,之后迅速补齐对外的渠道,让首轮扩散吸引到的用户能够根据官方的渠道进行进一步的了解,进一步的形成第二轮的声量扩散。
这种打法有没有很熟悉?公众号的推荐算法就是这个思路,新发的公众号会进行首轮推荐,数据表现好的话会进入到下一个流量池,之后以此类推。
所以,营销的内核,本质上是产品的硬核。从这次Manus获得的市场声量来看,也一定程度的说明了Manus的创新之处。如果要对这个硬核在进一步拆解的话,那就是连续创业背景的肖红、有技术天赋的季逸超、丰富产品经验的张涛。
最后,AI的进化速度会超越以往的任何一次科技革命,LLM的颠覆程度也远比人们想象的大,不过目前的现状是大家体感并不强烈,这可能主要是因为“生态”的发展是长期和缓慢的。汽车取代马车用了70年,这期间材料工程、汽车生产流水线、大规模道路基建、路政、司机、观念等,都需要逐步跟上。新技术往往带来新的机会,希望大家在AI的生态里,都能找到自己的定位。
- Author:Taylor
- URL:https://taylorai.top/article/1b12186a-d85d-80d3-8354-f9ac7e86d58e
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts




