

type
status
date
slug
summary
tags
category
icon
password
Transformer发展而来的LLM(大规模语言模型),以摧枯拉朽的势头强势出圈,生活里的方方面面都在发生着变革。新的更具智慧的大模型被不断的推出:GPT、BERT、T5,具有这么高智能的大模型,是如何被一步步训练出来的呢?
整体上,大模型训练需要经过四个关键环节:预训练、监督微调、奖励建模、RLHF(基于人类反馈的强化学习)。
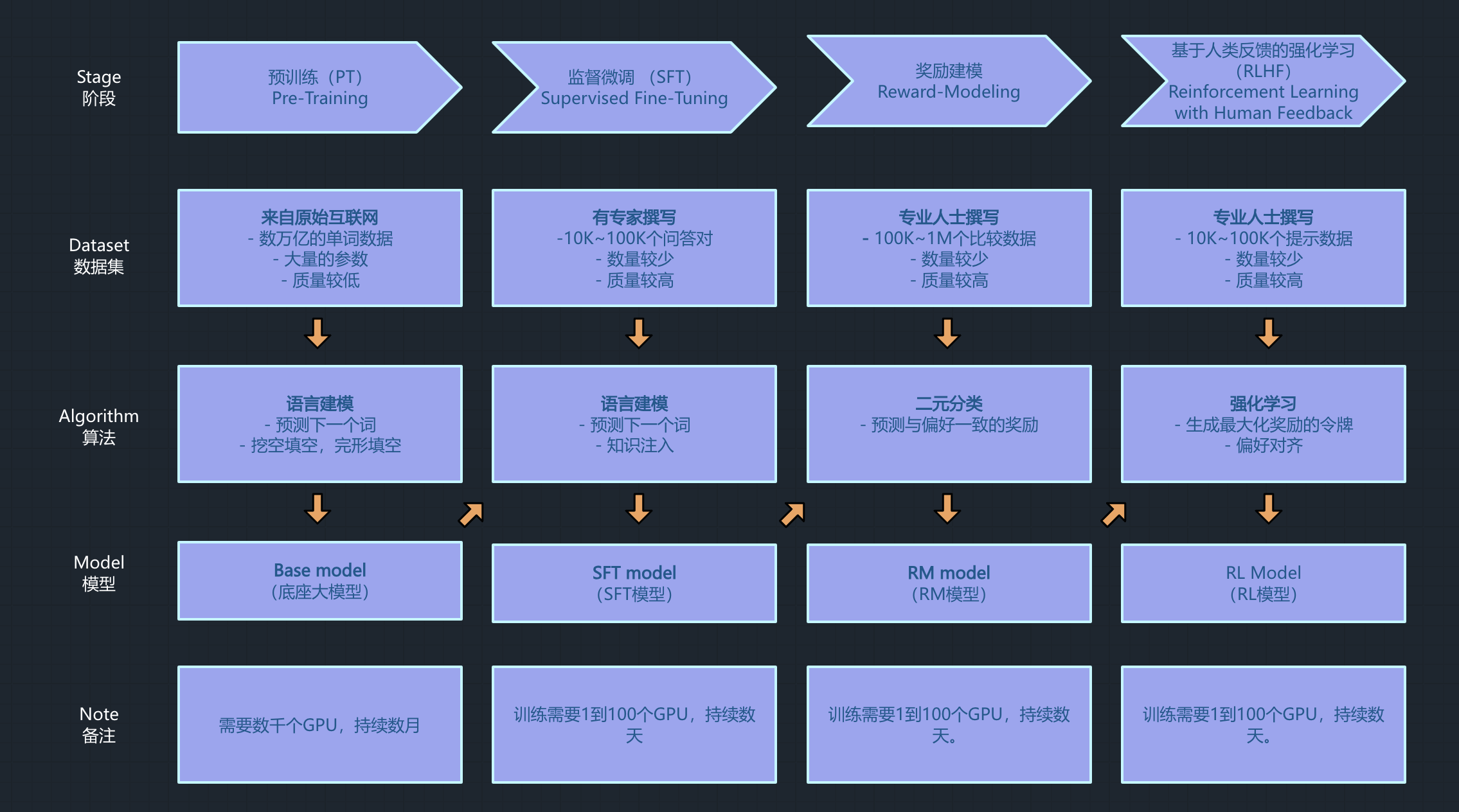
预训练让大模型从海量数据中学到通用知识,监督微调让大模型从”通才“到”专家“,强化学习阶段通过通过RM模型构建(reward modeling, rm)和PPO算法,塑造模型的价值观。
具体到工程实践,大模型的完整训练过程需要经过以下6步骤:
一、数据收集与准备
大模型预训练的第一步,就是为模型提供足够多的高质量数据,让模型学习语言的模式和知识。
大模型所需的语料库通常来源于互联网爬取(如Common Crawl)、领域专业数据(学术论文、代码库等)、对话数据集(社交媒体、客服记录)、书籍(如BooksCorpus)、维基百科、新闻文章等。例如,GPT-3的训练数据包含了数百亿甚至千亿级别的词量。
AI界有个大家都公认的理论,数据的质量决定算法的上限。所以在得到最初的数据之后,需要对数据进行清洗,以确保数据的质量。原始数据通常包含噪声,如HTML标签、广告文本、无意义的字符等。清洗过程包括:
- 去除无关内容和格式标记;
- 标准化文本(如统一大小写、规范化标点);
- 处理多语言数据(若需要多语言支持)。
- 隐私脱敏
- 文档分块
自然语言是人类能够正常理解,而对于大模型,则需要将自然语言处理成机器能够认识的内容。这里需要的工具就是分词(Tokenization):文本需要分解为模型可处理的单元(token)。
现代LLM常使用子词分词技术,如Byte-Pair Encoding(BPE)或WordPiece。这种方法通过将常见词保留为完整token,将稀有词拆分为子词单元,平衡了词汇表大小和语言表示能力。例如,“playing”可能被拆分为“play”和“ing”。
二、基于任务场景的模型架构设计
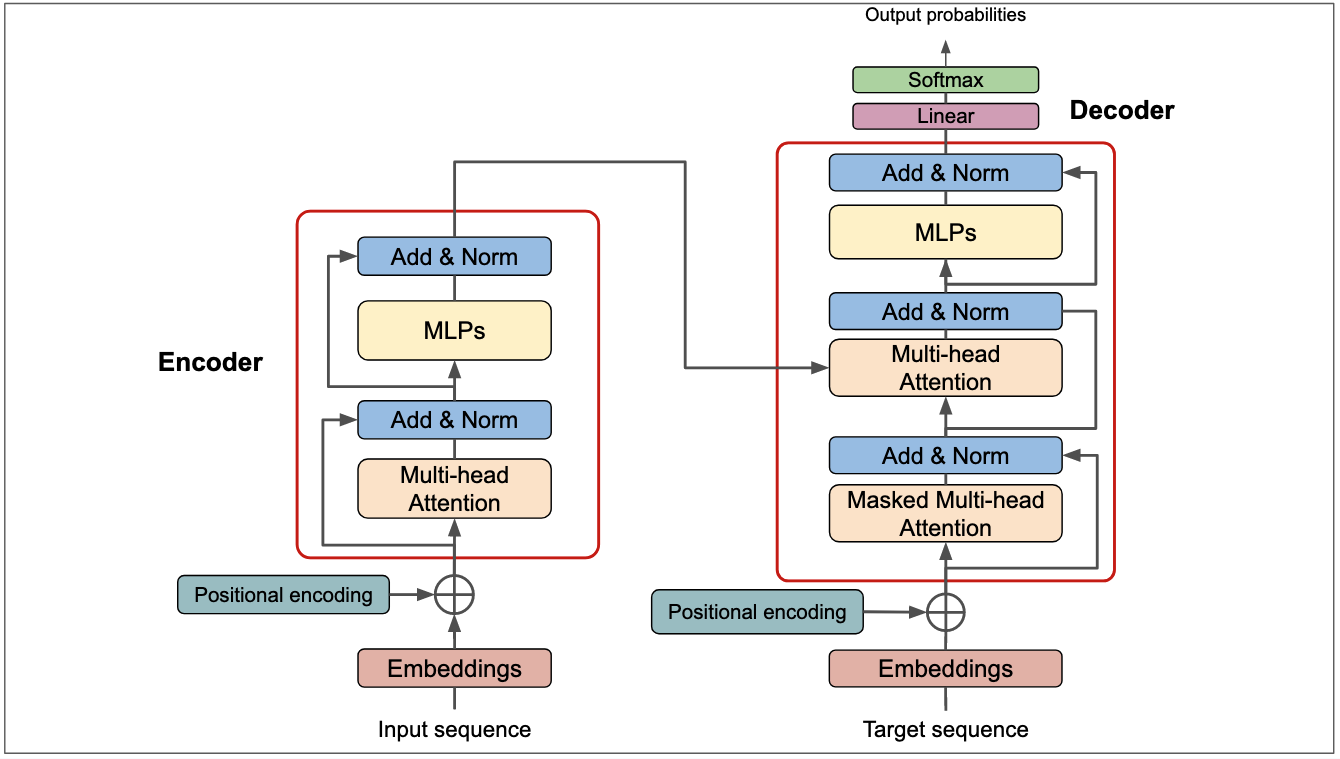
Transformer提供了LLM标准的算法框架,在面对不同任务场景时,可以对这个结构进行改造。此外,通过上图所示,Deocder其实也可以理解为Encoder+加上一个带掩码的注意力头。
以下是常见的变种模型结构:
- 仅解码器模型(如GPT系列):专注于生成任务,预测下一个词。
- 仅编码器模型(如BERT):专注于理解任务,通过双向上下文学习。
- 编码器-解码器模型(如T5):兼具理解和生成能力,适合翻译、摘要等。
配合不同的算法结构设计,大模型通常还设计有超参数,具体包括层数、注意力头数、隐藏层维度、上下文窗口等。常见的大模型超参数配置有:
参数量级 | 层数 | 注意力头数 | 隐层维度 |
1B | 24 | 16 | 4096 |
13B | 40 | 40 | 5120 |
175B | 96 | 96 | 12288 |
超参数设计越多,其预训练过程中需要的算力资源就越大,特别是2024年以来,大模型的参数规模普遍达到千亿级以上,通用型大模型预训练只能是大厂玩家可以玩得起。
由于Transformer自身不包含序列位置信息,位置编码(或称位置嵌入)被加入到输入嵌入中,帮助模型理解词序的重要性。Transformer通过位置编码为每个元素添加位置信息,具体来说就是使用正弦和余弦函数生成固定的位置向量,添加到输入的词嵌入中,目的在于帮助模型区分序列中元素的相对或绝对位置。直白一点理解就是将语言的顺序因素考虑进去,或者说是给无序的注意力加上“时间线”。
三、预训练:让大模型成为通才
这一步通常是利用无监督学习方法自回归语言建模(Causal Language Modeling),在大规模语料上训练模型,使其学习序列数据的语义、位置、上下文等信息。
预训练是大模型训练的核心阶段,使得模型学习到语言的通用表示。
在预训练的过程中,通常使用AdamW优化器,并配合学习率调度(如warm-up和衰减策略)来稳定训练。利用多GPU或TPU进行并行计算,加速训练过程,处理大规模数据。并实时监得控训练损失(loss)、困惑度(perplexity)等指标,根据需要调整训练策略。
四、微调:让大模型成为专才
经过预训练阶段,训练出来的主要是通用型大模型,但是面对特定领域,就需要对预训练出来的大模型进行一些微调,以使得大模型能适应特定的领域。
微调通常有两种方式,有监督微调(Supervised Fine-tuning SFT)和指令微调。这种重点讨论下SFT。
微调的主要步骤是:基于领域的专业数据集,在已有的大模型训练环节中,加入奖励模型和RLHF(基于人类反馈的强化学习)。在现在微调项目中,主要关注的是数据集和超参数的设置,还有算力资源的设计。
SFT使用人工标注的数据,对预训练出来的模型进行微调,使得在特定任务上表现更好,本质上是一个计算密集的过程,就是不断的通过编解码、前馈神经以及反向传播等算法,不断地调整参数权重,以找到一个超平面(函数关系)的过程。在开始训练之前,需要给大模型指定一些重要的训练参数,具体如下:
- 批量训练:数据被分为小批量(mini-batch),批量大小通常为128、256甚至更大,取决于硬件能力。
- 学习率调度:学习率动态调整,例如:
- Warm-up:初始学习率较小,逐渐增大;
- 衰减:后期逐渐减小,避免震荡。
- 并行化:LLM参数量巨大(如GPT-3有1750亿参数),训练需在多GPU或TPU上进行,采用:
- 数据并行:不同设备处理不同数据;
- 模型并行:模型参数分布在多设备上。
- 训练轮数:模型在整个数据集上训练多轮(epochs),通常为几轮到几十轮,视数据量和模型规模而定。
- 优化算法:使用Adam或AdamW等优化器,通过反向传播更新参数。
在训练的过程中,需要通过损失函数来提升模型的性能。比如用于衡量模型预测token与真实token之间的差异的交叉熵损失(Cross-Entropy Loss)。
现实环境中,绝大多数公司涉及到的是微调场景,具体关于微调的内容,作者之后再单独讨论。
五、大模型评估
对于预训练之后的通用大模型,评估其性能和泛化能力是至关重要的步骤。以下是常见的评估方法和方案,涵盖多个维度以全面检验模型的表现:
内在评估(Intrinsic Evaluation)
内在评估关注模型在预训练任务上的表现,主要衡量其对语言的基本理解和生成能力。
- 困惑度(Perplexity):用于评估语言生成模型(如GPT),通过测量模型对文本的预测能力来反映其语言理解水平。困惑度越低,模型表现越好。
- 准确率(Accuracy):在Masked Language Modeling(MLM)等任务中,评估模型预测被掩盖词的准确性。
外在评估(Extrinsic Evaluation)
外在评估将模型应用于具体任务,检验其在实际应用中的效果。
- 下游任务评估:将模型用于文本分类、问答、机器翻译或摘要生成等任务,采用任务特定的指标(如F1分数、BLEU、ROUGE等)衡量性能。
- 基准测试(Benchmarking):使用标准化数据集和指标,如GLUE、SuperGLUE或SQuAD,系统性地比较模型在多个任务上的表现。
泛化能力评估
泛化能力评估检验模型在不同场景下的适应性。
- 跨领域评估:在不同领域的数据集上测试模型,验证其对未见过领域数据的处理能力。
- 少样本学习(Few-shot Learning):评估模型在仅提供少量样本的情况下完成任务的能力,模拟数据稀缺的实际场景。
鲁棒性评估
鲁棒性评估确保模型在面对挑战性输入时仍能保持稳定。
- 对抗性测试(Adversarial Testing):通过引入对抗样本(如添加噪声或微小扰动),测试模型对攻击的抵抗能力。
- 偏见检测(Bias Detection):分析模型在不同群体或敏感属性上的表现,检测潜在偏见,确保公平性。
效率评估
效率评估关注模型在实际部署中的性能。
- 推理速度:测量模型在不同硬件上的推理时间,以满足实时性需求。
- 资源消耗:评估模型的内存占用和计算需求,优化部署成本。
可解释性评估
可解释性评估帮助理解模型的决策过程。
- 注意力可视化:分析模型的注意力机制,揭示其关注的核心特征。
- 特征重要性:识别对模型预测影响最大的输入特征,提升模型透明度。
用户反馈
用户反馈通过实际应用中的评价来优化模型。
- A/B测试:在真实环境中比较不同模型版本,观察用户满意度。
- 问卷调查:收集用户对模型输出质量的看法,作为改进依据。
通过以上方法,可以从内在能力、外在性能、泛化能力、鲁棒性、效率、可解释性以及用户体验等多个方面全面评估预训练后的通用大模型。这些评估结果为模型的优化和实际应用提供了重要依据。
六、模型部署与优化
让一个训练好的大模型部署上线,跟传统的搜索、推荐、广告中算法的部署过程类似。但生产环境中,要确保模型能够在生产环境中高效、安全、稳定地运行,就需要考虑一下几个方面:
大模型部署上线
大致的流程是,训练好的大模型需要经过转换和导出操作,将大模型部署的制定位置,然后经历容器化和API话,达到对外提供服务的状态。
模型导出转换环节,一般从训练框架PyTorch或者TensorFlow,导出更为通用的格式如ONNX或SavedModel。
为了更高效的在生产环境下运行大模型,可以考虑量化、剪枝、蒸馏等技术,在保持模型性能不变的同时,减少资源的消耗。
- 量化(Quantization):将模型权重从浮点数转换为低精度格式(如INT8),减小模型大小并加速推理。
- 剪枝(Pruning):移除模型中不重要的权重,进一步压缩模型。
- 蒸馏(Distillation):通过训练一个更小的模型来模仿大模型的行为,减少资源需求。
对于大模型的运行环境,可以根据应用场景选择合适的部署平台:
- 云平台:如AWS、Google Cloud、Azure,提供弹性计算资源和自动扩展能力,适合需要高可扩展性的场景。
- 边缘设备:如智能手机、IoT设备,适合需要低延迟或本地化处理的应用。
- 本地服务器:适合对数据隐私和安全有严格要求的企业。
现代应用服务的构建,为了方便迭代和运维管理,同样采用容器化的技术(Docker、Kubernetes),确保模型在不同环境中的一致性和可移植性。Docker将模型及其依赖(如库、配置文件)打包成Docker镜像,确保一致的运行环境。Kubernetes在需要大规模部署时,使用Kubernetes管理容器,实现自动化扩展和运维。
最后通过将大模型统一封装为API服务,方便企业内容和对外的调用。一般情况下可以采用基于HTTP协议的RESTful API。如果对延迟和吞吐量有更高的要求,可以考虑gRPC,如果是实时交互的应用场景(如对话系统),可以考虑WebSocket。
生产环境运维
围绕大模型服务的线上运行,还需要考虑服务的稳定性,实现服务的负载均衡和自动扩缩容。面对高并发请求,可以使用Nginx或HAProxy等工具,将请求分发到多个模型实例以提升并发能力。根据负载动态调整模型实例数量,确保服务的高可用性和稳定性,
此外需要对线上的大模型服务,实时监控模型运行状态并记录日志,便于优化和故障排查。监控方面可以使用Prometheus和Grafana等工具,监控延迟、吞吐量、错误率等性能指标。日志系统可以采用经典的ELK Stack(Elasticsearch、Logstash、Kibana)记录运行日志,分析问题根因。
大模型持续迭代
模型上线之后,通过不算的用户反馈,根据反馈保持定期的重新梳理数据以重新训练或微调,以提升模型性能和适应性。并且通过版本管理维护不同模型版本管理,通过CI/CD管道实现大模型的自动化测试、自动推送模型更新。
最后
以上主要介绍了通用型大模型的训练过程,主要包括了数据准备→模型架构设计→预训练→微调→评估→部署。
跟软件行业类似,大模型也是一个不断迭代的领域,这个迭代体现在训练所需的数据、AI算法框架、训练所需的芯片(集成电路)、以及客户的需求等。
对于通用大模型的训练流程,只有财大气粗的少数大厂玩家会涉及到以上全部流程,绝大部分的中小企业的做法是,由某个通用大模型并结合领域数据,微调出一个领域大模型,然后通过服务化的方式,应用到企业内外应用场景。
下一章节,将会讨论企业环境下的大模型微调实战。欢迎关注。
- Author:Taylor
- URL:https://taylorai.top/article/1cf2186a-d85d-8054-af8b-f947de83af76
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts




